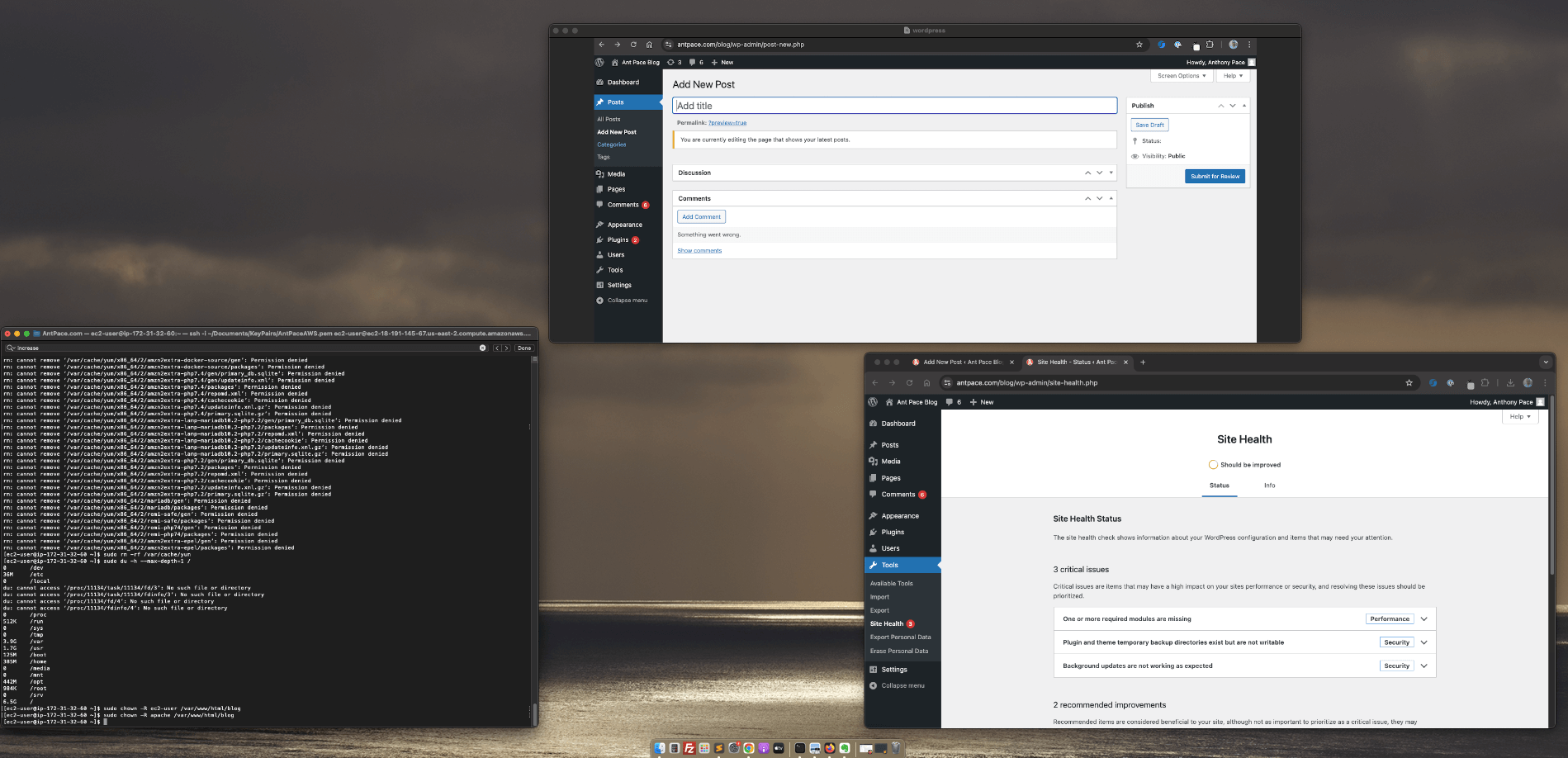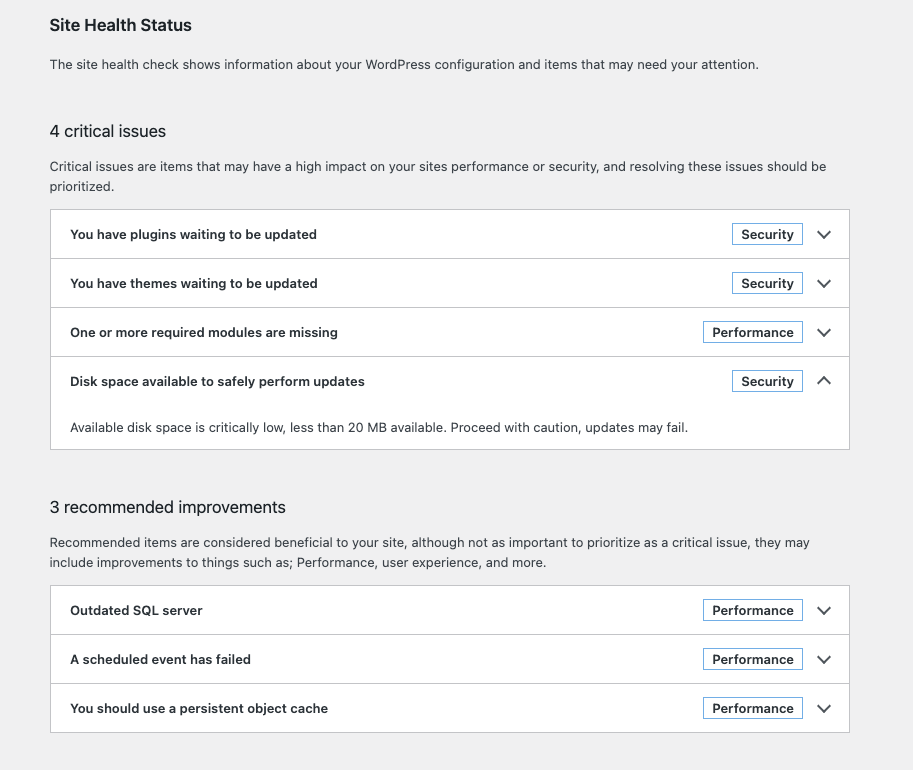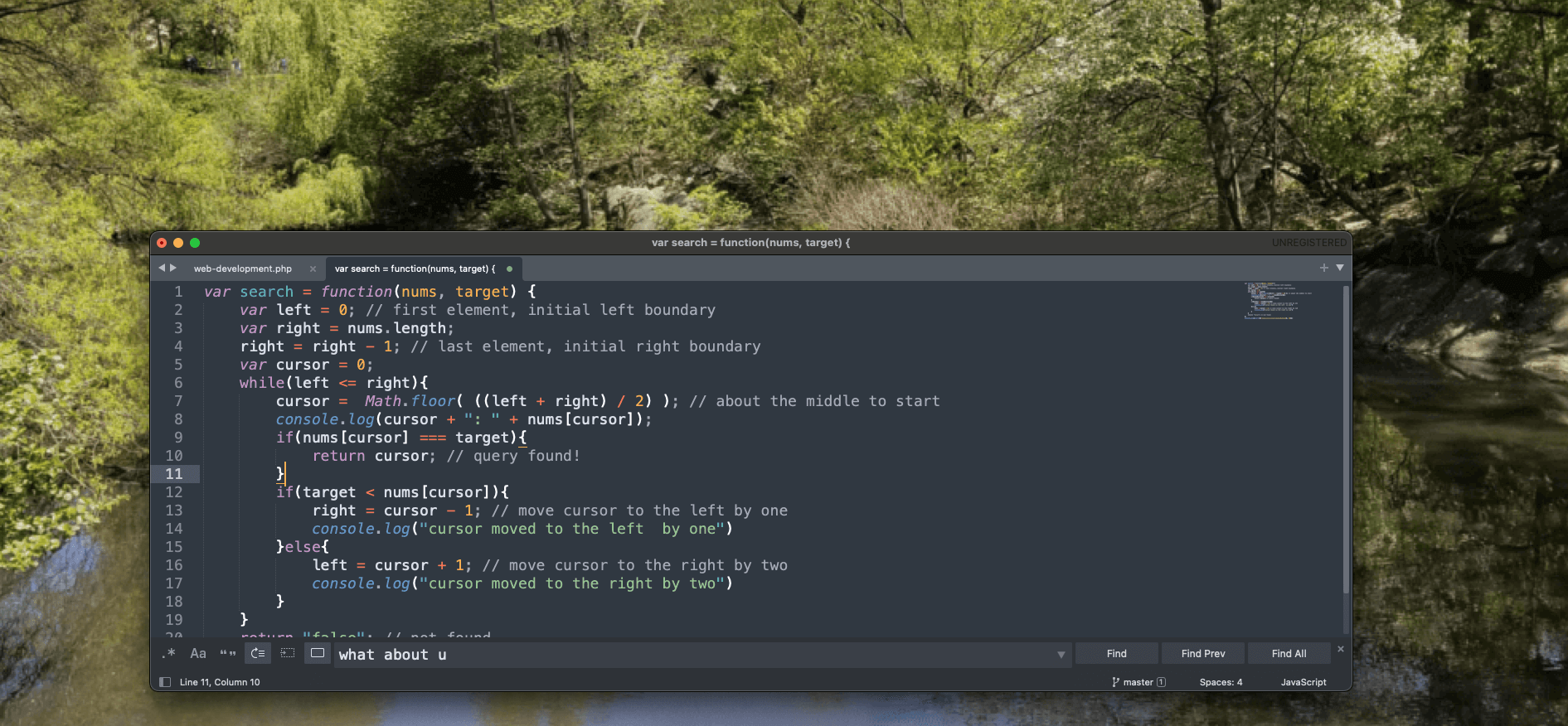
Parallax scrolling is a technique where the background moves at a different speed than the foreground. Ideally, the effect has many layers: a background, a mid-ground, and a foreground. These layers moving at different speeds create the illusion of depth and immersion
- The background layer forms the foundation of the parallax effect. It typically consists of large, visually captivating images or patterns that set the scene and establish the mood of the website.
- The mid-ground layer serves as an intermediary between the background and foreground, providing additional visual interest and depth.
- The foreground layer contains the primary content and interactive elements that users engage with directly.
My favorite example comes from the classic Sonic the Hedgehog game on the Sega Genesis. In that game, the background layer encompasses lush landscapes, while the intermediate layer consists of trees and obstacles that add depth to the scene. Sonic and collectibles represent the foreground layer, with Sonic’s speedy movements contrasting the slower-paced background and intermediate layers.
HTML & CSS Parallax Effect
We can use HTML and CSS to achieve a parallax scrolling effect by manipulating the position and properties of background images or layers.
HTML:
<div class="parallax-container">
<div class="parallax-background"></div>
<div class="content">
<!-- Your content here -->
</div>
</div>
CSS:
.parallax-container {
position: relative;
overflow-x: hidden;
overflow-y: auto; /* Enable vertical scrolling */
height: 100vh; /* Set the container height to full viewport height */
}
.parallax-background {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 200%; /* Adjust height to create a taller background for parallax effect */
background-image: url('background.jpg');
background-size: cover;
background-position: center;
z-index: -1; /* Ensure background is behind content */
}
.content {
padding: 20px;
/* Other styles for your content */
}
- The
.parallax-containerserves as the main container for the parallax effect. It has relative positioning to contain the absolutely positioned background layer. - The
.parallax-backgrounddiv contains the background image. It’s absolutely positioned to cover the entire container and set behind the content with a negative z-index. - Adjusting the height of
.parallax-backgroundto be taller than the container creates the parallax effect when the user scrolls. - The
.contentdiv holds the content and is positioned over the parallax background.
My Background Webpage
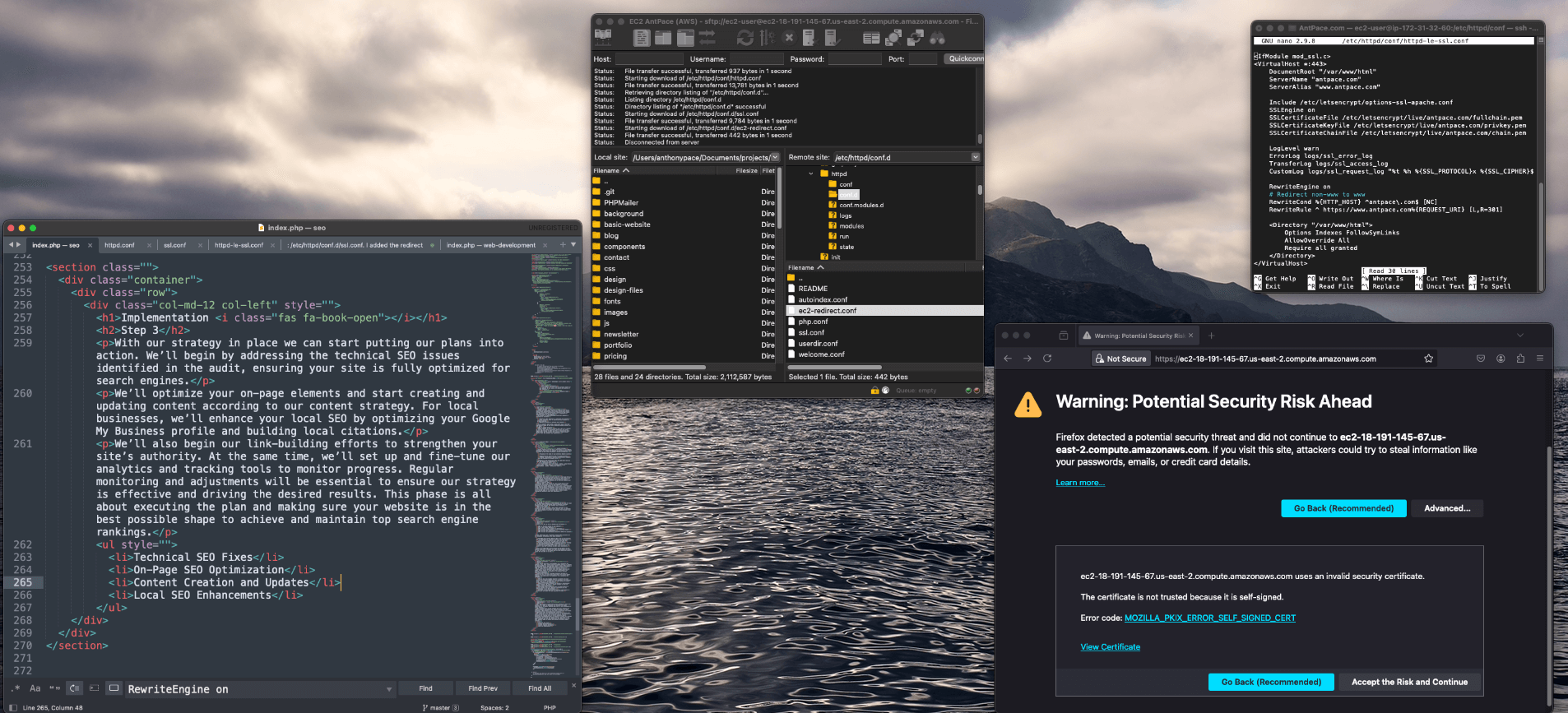
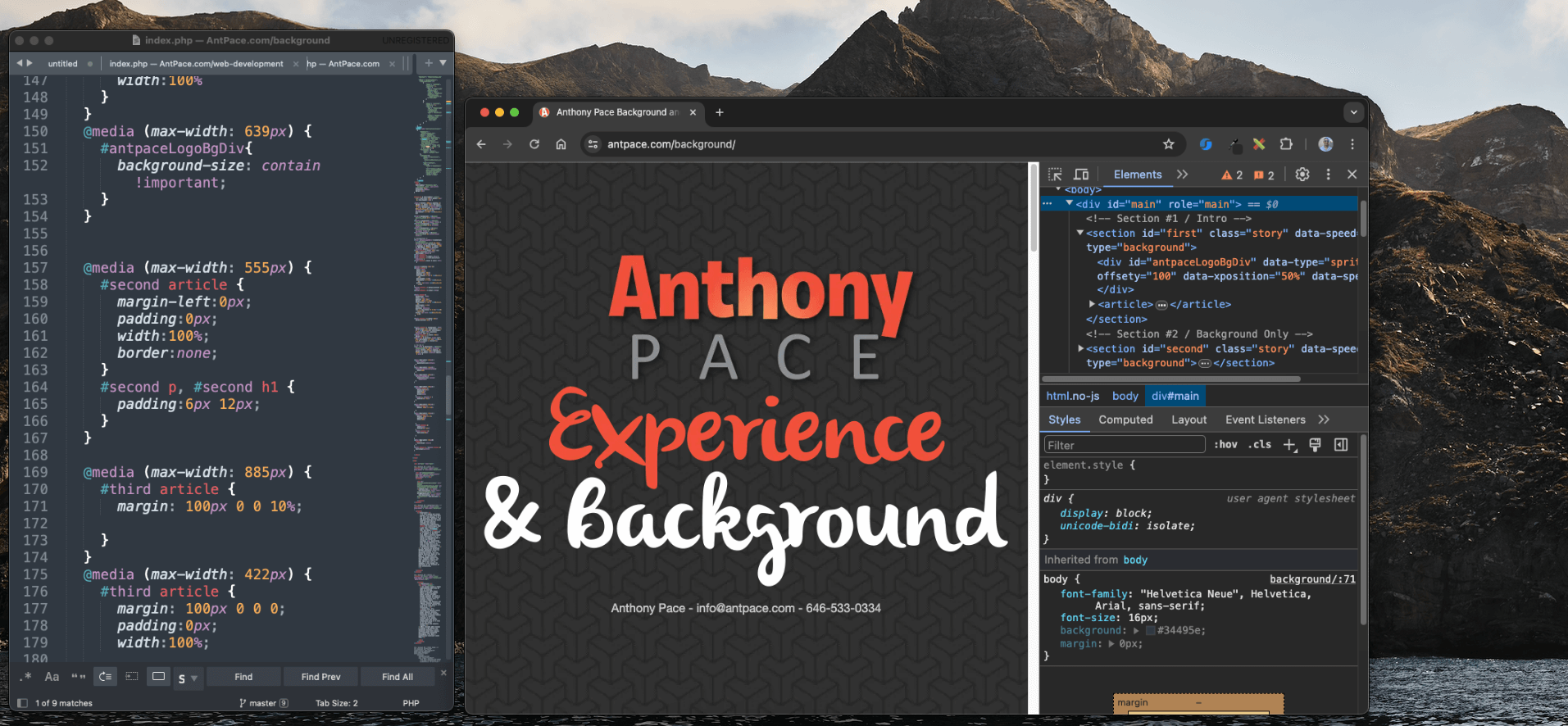
A few years ago, I made a single webpage to describe my professional background and experience. I decided to use a parallax background effect for this page. You can visit it here.
I really love the way the main logo text initially seems to blend into the foreground but remains static as you scroll. Upon scrolling, you’ll observe that the top text remains fixed while the second line moves independently, creating a distinct visual effect. It feels unexpected. The contrasting image backgrounds creates a fun juxtaposition.
And, it’s all done with CSS (no JavaScript necessary). You can create a simple parallax effect by adjusting the positioning of background images or layers using CSS properties like background-position and background-attachment. This allows the background to move at a different rate than the foreground content as the user scrolls, creating the illusion of depth.
Here is the code that I used to build this example:
<!doctype html>
<html class="no-js" lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<link rel="shortcut icon" href="https://www.antpace.com/favicon.ico" />
<link rel="apple-touch-icon-precomposed" sizes="144x144" href="https://www.antpace.com/apple-touch-icon-144x144-precomposed.png">
<link rel="apple-touch-icon-precomposed" sizes="114x114" href="https://www.antpace.com/apple-touch-icon-114x114-precomposed.png">
<link rel="apple-touch-icon-precomposed" sizes="72x72" href="https://www.antpace.com/apple-touch-icon-72x72-precomposed.png">
<link rel="apple-touch-icon-precomposed" sizes="57x57" href="https://www.antpace.com/apple-touch-icon-57x57-precomposed.png">
<link rel="apple-touch-icon-precomposed" href="https://www.antpace.com/apple-touch-icon-precomposed.png">
<title>Anthony Pace Background and Experience</title>
<meta name="description" content="Anthony Pace is a web developer, designer, and database architect. His daily work includes writing software and creating user-centered experiences. The technologies that he use most frequently are HTML5, CSS3, Javascript, PHP, and MySql.">
<meta name="keywords" content="Anthony Pace, web, development, design, marketing, websites, creative services, Bronx, New York">
<meta name="viewport" content="width=device-width">
<link rel="stylesheet" href="https://use.fontawesome.com/releases/v5.5.0/css/all.css" integrity="sha384-B4dIYHKNBt8Bc12p+WXckhzcICo0wtJAoU8YZTY5qE0Id1GSseTk6S+L3BlXeVIU" crossorigin="anonymous">
<link href='https://fonts.googleapis.com/css?family=Lobster+Two:700&v2' rel='stylesheet' type='text/css'>
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1,
"item": {
"@id": "https://www.antpace.com",
"name": "Home",
"image": "https://www.antpace.com/images/anthony-pace-logo.webp"
}
},
{
"@type": "ListItem",
"position": 2,
"item": {
"@id": "https://www.antpace.com/background",
"name": "Background",
"image": "https://www.antpace.com/background/logo.webp"
}
}
]
}
</script>
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "WebPage",
"name": "Anthony Pace Background & Experience",
"description": "The page describes Anthony's professional background and experience.",
"lastReviewed": "<?php echo date("Y-m-d", time() - 60 * 60 * 24); ?>",
"reviewedBy": {
"@type": "Person",
"name": "Anthony Pace"
},
"publisher":{
"@type":"Organization",
"url":"https://www.antpace.com",
"name":"AntPace",
"logo":{
"@type":"ImageObject",
"url":"https://www.antpace.com/images/anthony-pace-logo.webp",
"width":"490px",
"height":"230px"
}
}
}
</script>
<style>
body {
font-family: "Helvetica Neue", Helvetica, Arial, sans-serif;
font-size: 16px;
background:#34495e;
margin: 0px;
}
article h1 { font-family: 'Lobster Two'; font-size: 60px; margin: 25px 0; line-height: 1em; }
.story { height: 1000px; padding: 0; margin: 0; width: 100%; max-width: 1920px; position: relative; margin: 0 auto; border-top: 1px solid rgba(255,255,255,0.3); border-bottom: 1px solid rgba(0,0,0,0.4); box-shadow: 0 0 50px rgba(0,0,0,0.8);}
#first { background: url(images/textured.webp) 50% 0 repeat fixed; }
#second { background: url(images/ufo.webp) 50% 0 no-repeat fixed; }
#fourth { background: url(images/abstract2.webp) 50% 0 no-repeat fixed; }
#third { background: url(images/desertEarthSet.webp) 50% 0 no-repeat fixed; }
#last { background: url(images/textured.webp) 50% bottom repeat fixed; }
/* Introduction */
#first #antpaceLogoBgDiv { background: url(/images/anthony-pace-logo.webp) 50% 100px no-repeat fixed; min-height: 1000px; padding: 0; margin: 0; width: 100%; max-width: 1920px; position: relative; margin: 0 auto; }
#first article { width: 100%; top: 300px; position: absolute; text-align: center; }
#first article p,
#first article a { color: #ccc; }
#first article a { text-decoration: underline; }
#first article a:hover { color: #fff; }
#second { padding: 50px 0;}
#second article {
color: #fff;
width: 445px;
margin-left: 100px;
padding: 10px 20px;
text-shadow: 0 -1px 0 rgba(0,0,0,0.5);
line-height: 1.5em;
box-shadow: 0 0 25px rgba(0,0,0,0.3);
border: 1px solid rgba(150,150,150,0.1);
}
#second article p { margin-bottom: 25px; }
#second article a { color: #ff0;}
#third article {
background: #333;
color: #fff;
padding: 10px 20px;
margin: 100px 0 0 60%;
text-shadow: 0 -1px 0 rgba(0,0,0,0.5);
line-height: 1.5em;
color: #fff;
position: absolute;
top: 0; box-shadow: 0 0 25px rgba(0,0,0,0.3);
border: 1px solid rgba(150,150,150,0.1);
}
#third article p { width: 300px; margin-bottom: 25px; }
#fourth article { background: #333;margin-left: 10%; text-shadow: 0 -1px 0 rgba(0,0,0,0.5); line-height: 1.5em; color: #fff; position: absolute; top: 0; }
#fourth article p { width: 300px; margin: 50px 0; }
#fourth img { position: fixed; left: 50%; box-shadow: 0 0 25px rgba(0,0,0,0.7); z-index: 1; border:5px solid white;}
/* The End */
#last .last { background: url(images/thanks.webp) 50% 100px no-repeat fixed; height: 1000px; padding: 0; margin: 0; width: 100%; max-width: 1920px; position: relative; margin: 0 auto; }
@media (max-width: 625px) {
#last .last {
background-size:contain;
}
}
@media (max-width: 711px) {
#experienceAndBackgroundImg{
width:100%
}
}
@media (max-width: 639px) {
#antpaceLogoBgDiv{
background-size: contain !important;
}
}
@media (max-width: 555px) {
#second article {
margin-left:0px;
padding:0px;
width:100%;
border:none;
}
#second p, #second h1 {
padding:6px 12px;
}
}
@media (max-width: 885px) {
#third article {
margin: 100px 0 0 10%;
}
}
@media (max-width: 422px) {
#third article {
margin: 100px 0 0 0;
padding:0px;
width:100%;
}
#third article p{
width:auto;
padding:6px 12px;
}
#third article h1{
font-size:50px;
}
}
@media (max-width: 767px){
footer {
text-align: center;
}
}
#third article p, #second article p{
text-align:justify;
}
</style>
</head>
<body>
<div id="main" role="main">
<!-- Section #1 / Intro -->
<section id="first" class="story" data-speed="8" data-type="background">
<div id="antpaceLogoBgDiv" data-type="sprite" data-offsetY="100" data-Xposition="50%" data-speed="-2"></div>
<article>
<img id="experienceAndBackgroundImg" src="images/experienceAndBackground.webp" alt="Experience and Background" />
<p>Anthony Pace - <a style="text-decoration: none;" href="mailto:info@antpace.com">info@antpace.com</a> - <a style="text-decoration: none;" href="tel:6465330334">646-533-0334</a></p>
</article>
</section>
<!-- Section #2 / Background Only -->
<section id="second" class="story" data-speed="4" data-type="background">
<article>
<h1>Experience</h1>
<p>I love coding and visual design. I've been doing both for over two decades. I am a web developer, designer, and database architect. My daily work includes writing software and creating user-centered experiences. <strong>The technologies that I use most frequently are HTML5, CSS3, Javascript, PHP, and MySQL.</strong> </p>
<p>Currently, I am employed by a company in New York City where I directly manage other developers. I am in charge of developing apps (native and HTML5) and building & maintaining data driven websites. I also play a large role in the strategy and implementation of marketing campaigns. </p>
<p> My position as marketing manager emphasizes measuring the effectiveness of our marketing actions, and then making decisions based on the data. I use advanced A/B testing, google analytics, email campaign reports, and user surveys to figure out what works best for the company. I also manage the logistics of our presence at live exhibitions.
</p>
</article>
</section>
<!-- Section #3 / Photos -->
<section id="third" class="story" data-speed="6" data-type="background" data-offsetY="250">
<article>
<h1>Background</h1>
<div class="textbox">
<p>In primary school I began experimenting with HTML as well as creating applications with Visual Basic. I quickly learned about various software design concepts and built a strong interest in Computer Science. Despite this, in college I studied philosophy. The abstract and logical thinking techniques I fostered have applied very much to my career in technology. </p>
<p>Since then, I've continued to educate myself about computer science. Books and online lectures facilitate me moving towards a level of expertise relevant to my career. Social media and online communities help me to keep up on the latest technologies and industry trends.</p>
<p>When finished with college I created a web design and marketing business. I built clientele using both digital and traditional marketing strategies. I've been a professional developer since 2008.</p>
</div>
</article>
</section>
<!-- Section #4 / HTML5 Video -->
<!--<section id="fourth" class="story" data-speed="8" data-type="background" data-offsetY="250">
<article>
<h2>Skills</h2>
<div class="textbox">
<p>I have acquired and honed a variety of abilities as a technologist. I am a full stack web developer with a passion for programming. Some of the most useful skills that I have built include:
<ul>
<li>Project Management
<li>Business Management
<li>Design
<li>Software Engineering
<li>Marketing
</ul>
</p>For a more technical description of my abilites please visit my <a style="color:white;" href="http://antpace.com/resume" target="_blank">resumé</a>.</p>
</div>
</article>
</section> -->
<!-- Section #5 / The End-->
<section id="last" data-speed="8" data-type="background" data-offsetY="250">
<a href="/blog/"><div class="last" data-type="sprite" data-offsetY="-1600" data-Xposition="50%" data-speed="-2"></div> </a>
<p style=" text-align: center; padding: 50px;font-size: 24px;"><a href="/blog/about/" style="color:white; text-decoration: none;">Continue to my blog <i class="fas fa-arrow-right"></i></a></p>
</section>
</div> <!-- // End of #main -->
<?php include $_SERVER["DOCUMENT_ROOT"] . '/footer-shared.php'; ?>
<?php include $_SERVER["DOCUMENT_ROOT"] . '/components/analytics.php'; ?>
</body>
</html>
Take a look:
References:
- https://www.clickrain.com/blog/parallax-scrolling-examples-and-history
- https://en.wikipedia.org/wiki/Parallax_scrolling
- https://www.w3schools.com/howto/howto_css_parallax.asp