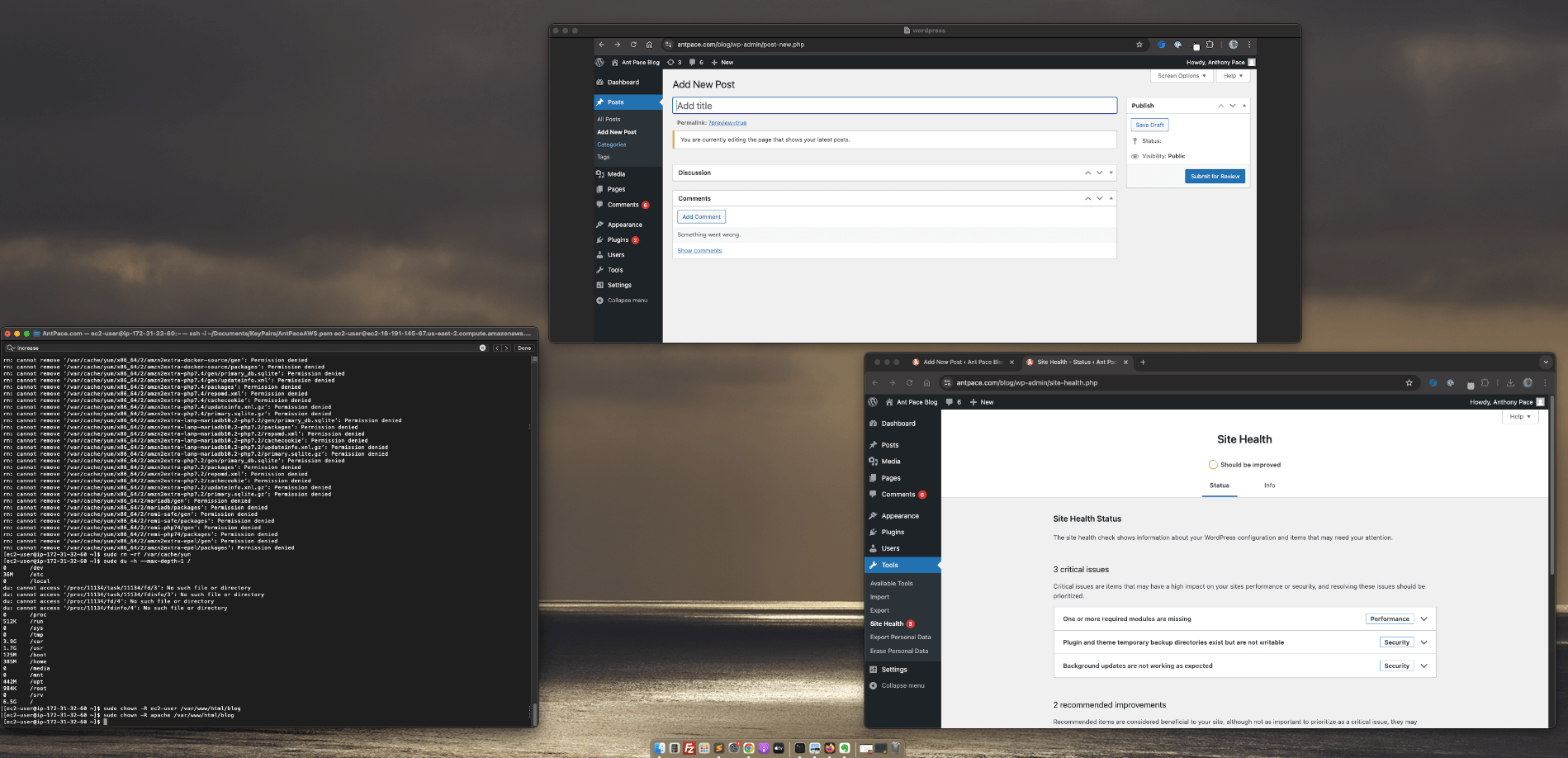
I run this website on a t2.micro EC2 instance. It only has 8 gigabytes of storage space. The blog runs on WordPress. I tried creating a new post recently, but it wouldn’t let me publish.
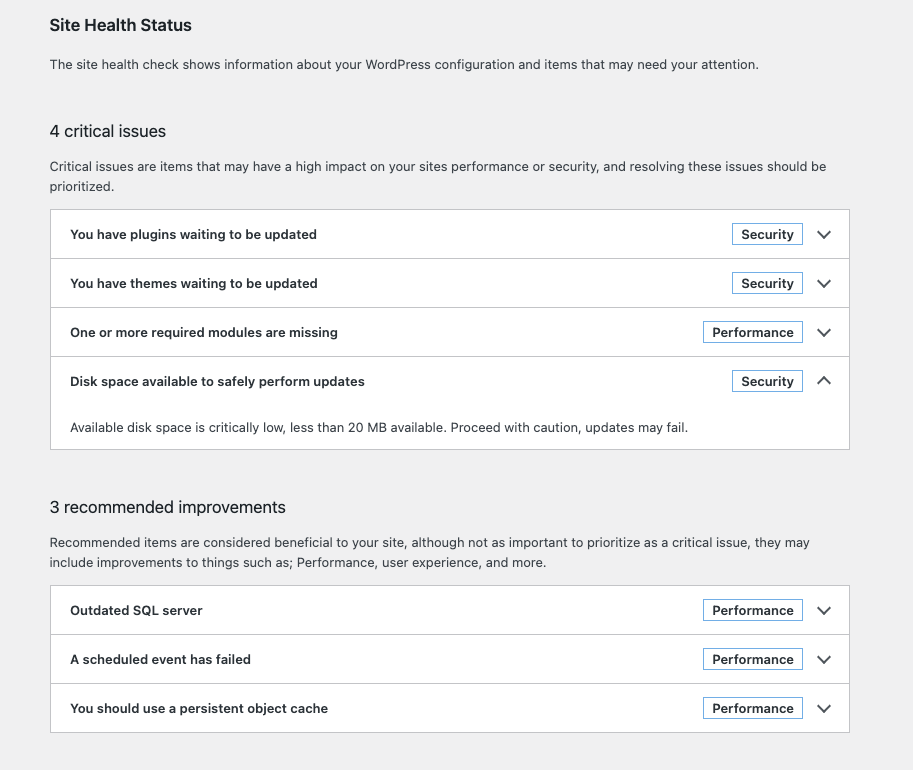
A vague message told me I was “editing the page that shows your latest posts” – even though I wasn’t. I checked the dashboard site health, and noticed that somethings needed updating, but disk space was critically low.
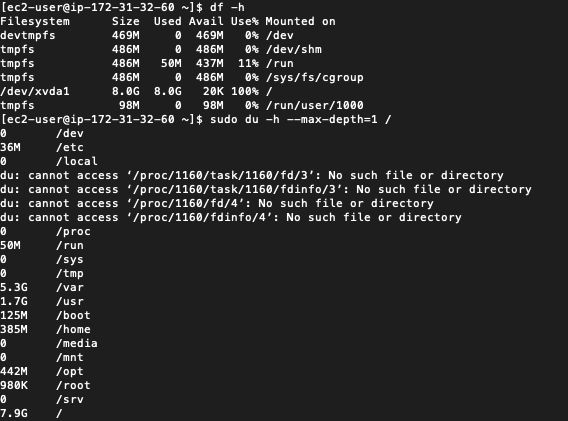
I SSH’d into the instance was able to confirm that 100% of the 8 gigabytes was in use: `df -h`
I was able to use the ‘disk usage’ command to drill down and find large directories: ‘sudo du -h –max-depth=1 /var’. I was able to clean up unused yum packages, logs, and cache to clear up over a gigabyte of space.
sudo journalctl --vacuum-size=100M
sudo yum clean all
rm -rf /var/cache/yum
It looks like there are some database files that could be cleaned up too, but I’ll wait for now. I think my next course of action, when this inevitably happens again, will be to increase my disk space by expanding my EBS volume and resizing the file system.
Playing with databases and storage can be dangerous. Make sure you always have a back-up strategy and disaster recovery plan.
I discovered a bug in a web app that I built a few years ago. It was difficult to debug because it only happened intermittently. As any programmer knows, issues that can’t be reproduced consistently (and locally) present the most pain. Ultimately, it was causing database records to be created in double – but only when certain conditions evaluated true in the app state.
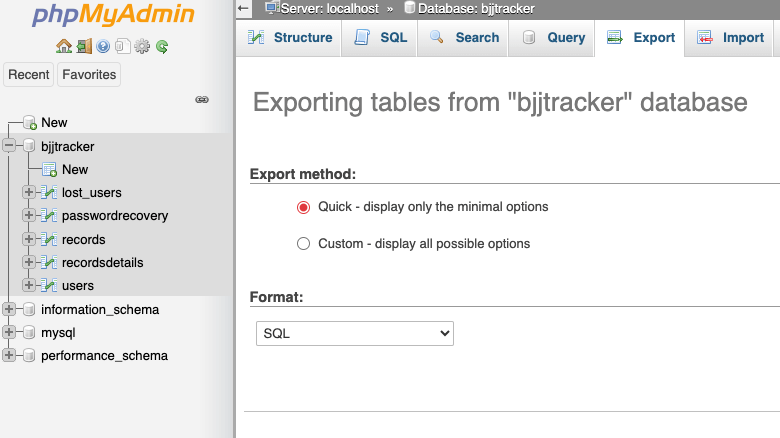
I’ll get into the code fix in another post. Here, I’ll show you how I cleaned up the database. This application has over ten-thousand data records in production. The first thing I did before messing around was to export a back-up of the prod DB. That was only me being extra careful – I already have a nightly job that dumps the entire production database as a .sql file to an S3 bucket. Taking an export on the fly is easy through phpMyAdmin.
Export database from phpMyAdmin
Step one is to identify duplicates and store them in a temporary table, using a GROUP BY clause. In MySQL (and most other SQL-based database systems),GROUP BY is used to group rows from a table based on one or more columns.
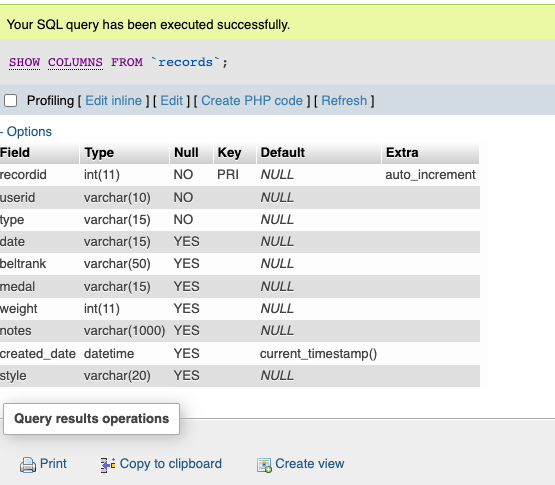
The duplicate rows that I am interested in have all identical values, except for their primary keys. I can group those rows (and put them into a new, temporary, table) by including all of the table columns names (except the primary key) in my SQL statement. You can list those names in phpMyAdmin with this command:
SHOW COLUMNS FROM `records`;
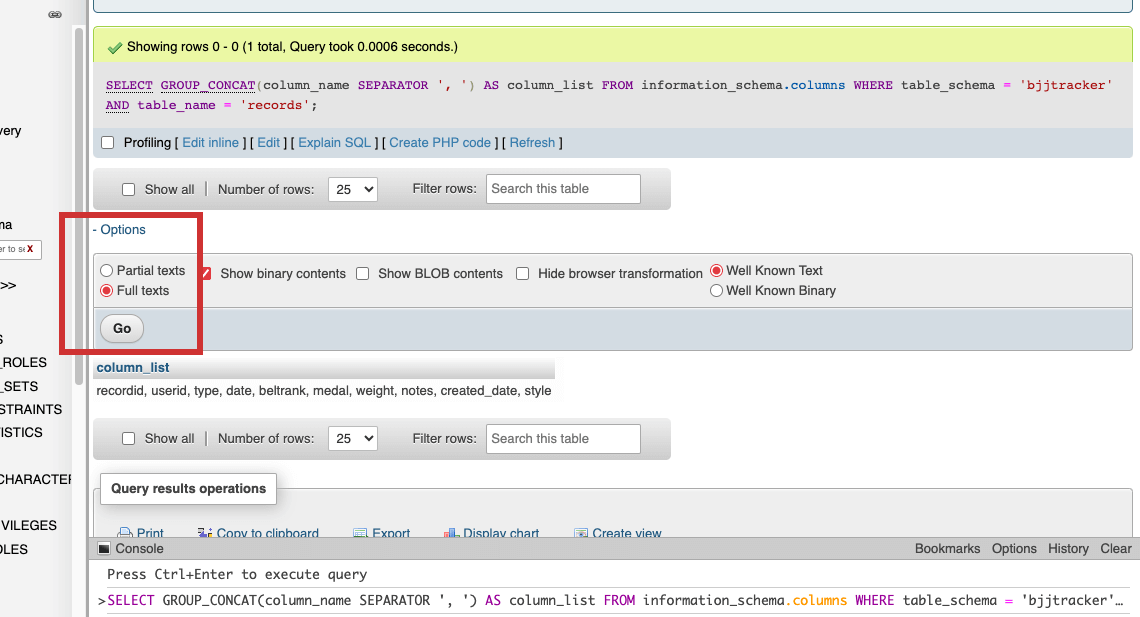
My tables have quite a few columns. Instead of copy/pasting each field name, I used SQL code to list them out together. This was possible by leveraging the INFORMATION_SCHEMA database, a special system database that provides metadata about the database server itself in MySQL. I could retrieve the column names and then concatenate them into a single string using the GROUP_CONCAT function:
SELECT GROUP_CONCAT(column_name SEPARATOR ', ') AS column_list
FROM information_schema.columns
WHERE table_schema = 'bjjtracker'
AND table_name = 'records';
The result displayed as abbreviated until I selected “Full texts” from the options menu (highlighted below)
I could now copy/paste that column_list into my SQL statement. Remove the primary key field (usually the first one), or else no duplicates will be found (unless your use-case involves records having repeated primary key values, which is a less likely scenario).
CREATE TABLE TempTable AS
SELECT userid, type, date, beltrank, medal, weight, notes, created_date, style -- List all columns except the primary key
FROM `records`
GROUP BY userid, type, date, beltrank, medal, weight, notes, created_date, style -- Group by all columns except the primary key
HAVING COUNT(*) > 1; -- Indicates their is more than one record with exactly matching values
Now we have a new table that contains records that are duplicative in our original table. Step 2 is to delete the duplicates from the original table.
DELETE FROM `records`
WHERE (userid, type, date, beltrank, medal, weight, notes, created_date, style) IN (
SELECT userid, type, date, beltrank, medal, weight, notes, created_date, style
FROM TempTable
);
Don’t forget to delete that temporary table before you leave:
DROP TEMPORARY TABLE IF EXISTS TempTable;
Dealing with NULL values
On the first table I used this on, everything worked as expected. On a subsequent run against another table, zero rows were deleted even though my temp table contained duplicate records. I deduced that it was because of NULL values causing the comparison to not work as expected. I figured that I had to handle NULL values explicitly using the IS NULL condition on each field.
DELETE FROM recordsdetails
WHERE
(userid IS NULL OR userid,
recordid IS NULL OR recordid,
detailtype IS NULL OR detailtype,
technique IS NULL OR technique,
reps IS NULL OR reps,
partnername IS NULL OR partnername,
partnerrank IS NULL OR partnerrank,
pointsscored IS NULL OR pointsscored,
pointsgiven IS NULL OR pointsgiven,
taps IS NULL OR taps,
tappedout IS NULL OR tappedout,
result IS NULL OR result,
finish IS NULL OR finish,
created_date IS NULL OR created_date)
IN (
SELECT userid, recordid, detailtype, technique, reps, partnername, partnerrank, pointsscored, pointsgiven, taps, tappedout, result, finish, created_date
FROM TempTable
);
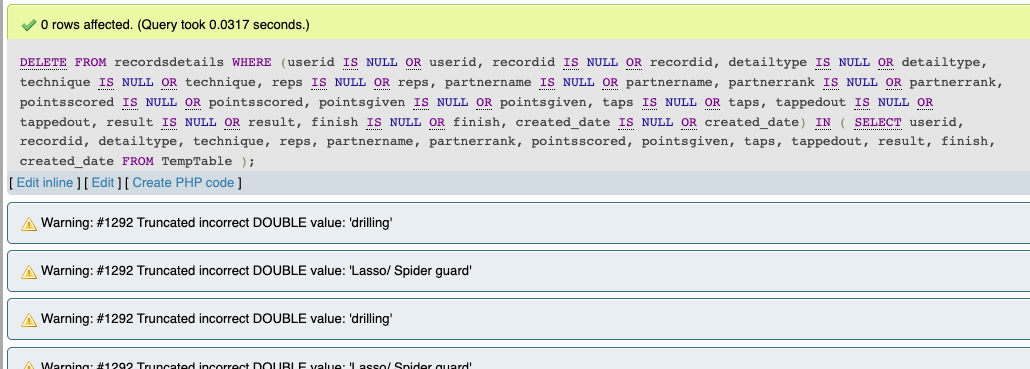
But yet, I still got zero rows being deleted. This time though, I was seeing a warning. It complained: “Warning: #1292 Truncated incorrect DOUBLE value”
This suggests that there is a data type mismatch or issue in the comparison involving numeric and string values. My guess is that the IS NULL handling was causing type conversion issues. To remedy this, I wrote a more explicit query by combining the AND and OR conditions.
DELETE FROM recordsdetails
WHERE
(userid IS NULL OR userid IN (SELECT userid FROM TempTable)) AND
(recordid IS NULL OR recordid IN (SELECT recordid FROM TempTable)) AND
(detailtype IS NULL OR detailtype IN (SELECT detailtype FROM TempTable)) AND
(technique IS NULL OR technique IN (SELECT technique FROM TempTable)) AND
(reps IS NULL OR reps IN (SELECT reps FROM TempTable)) AND
(partnername IS NULL OR partnername IN (SELECT partnername FROM TempTable)) AND
(partnerrank IS NULL OR partnerrank IN (SELECT partnerrank FROM TempTable)) AND
(pointsscored IS NULL OR pointsscored IN (SELECT pointsscored FROM TempTable)) AND
(pointsgiven IS NULL OR pointsgiven IN (SELECT pointsgiven FROM TempTable)) AND
(taps IS NULL OR taps IN (SELECT taps FROM TempTable)) AND
(tappedout IS NULL OR tappedout IN (SELECT tappedout FROM TempTable)) AND
(result IS NULL OR result IN (SELECT result FROM TempTable)) AND
(finish IS NULL OR finish IN (SELECT finish FROM TempTable)) AND
(created_date IS NULL OR created_date IN (SELECT created_date FROM TempTable));
That worked! With a cleaned database, it was time to figure out what was causing the bug in the first place, and to fix the problem.
Clones in quiet dance; Copies of our code converge; Echoes of our souls;
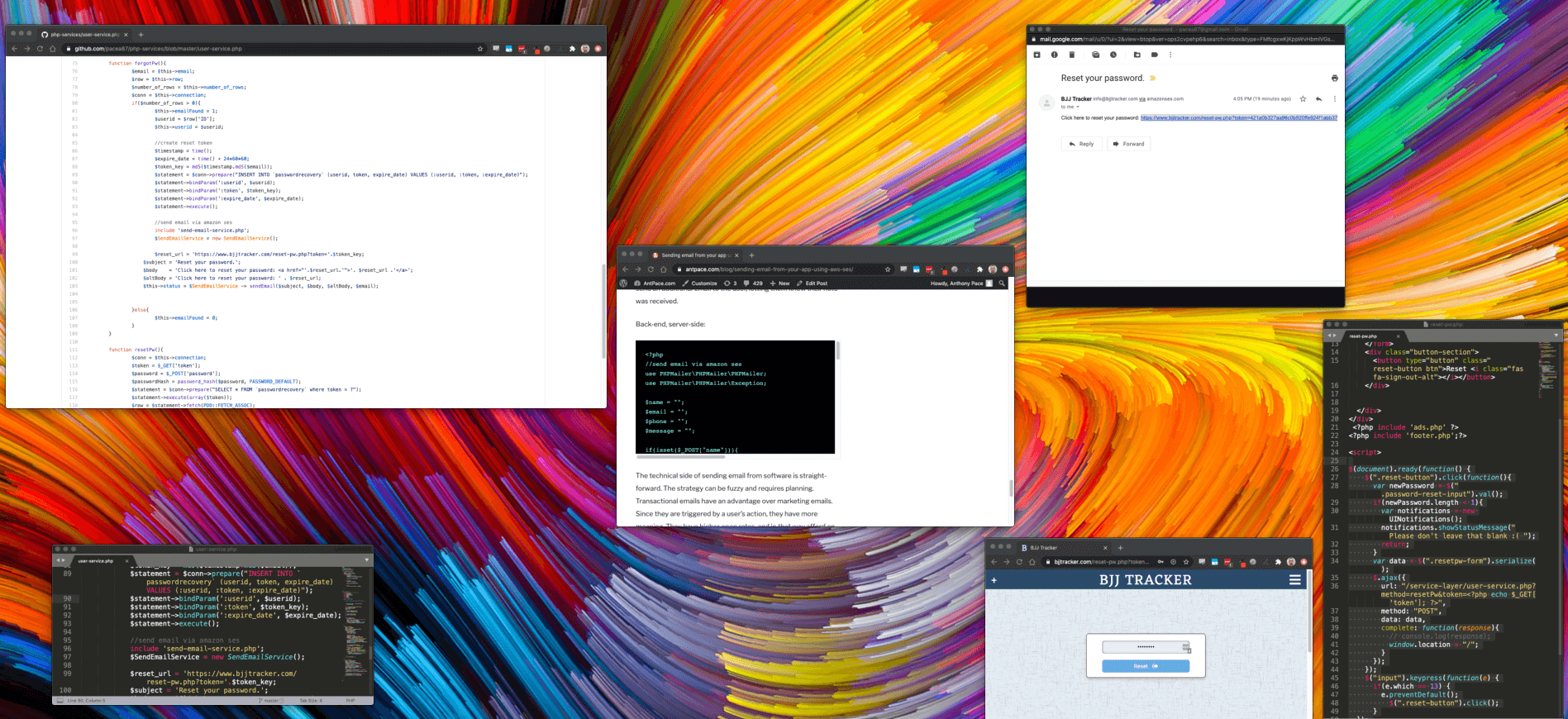
My email account is a skeleton key to anything online I’ve signed up for. If I forget a password, I can reset it. Implementing this feature for a web app takes just a few steps.
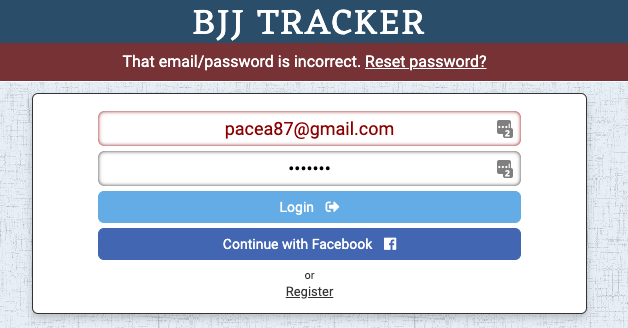
When users enter an incorrect password, I prompt them to reset it.
Clicking the reset link calls a “forgot password” back-end service.
$(document).on("click",".reset-pw-cta", function(){
var email = $(this).attr("data");
$.ajax({
url:"/service-layer/user-service.php?method=forgotPw&email="+email,
complete:function(response){
console.log(response.responseText)
window.showStatusMessage("A password reset email as been sent to " + email);
}
})
});
A token is created in our ‘password recovery’ database table. That token is related back to an account record.
As a security practice, recovery tokens are deleted nightly by a cron job.
An email is then sent containing a “reset password” link embedded with the token. AWS SES and PHPMailer is used to send that message.
function forgotPw(){
$email = $this->email;
$row = $this->row;
$number_of_rows = $this->number_of_rows;
$conn = $this->connection;
if($number_of_rows > 0){
$this->emailFound = 1;
$userid = $row['ID'];
$this->userid = $userid;
//create reset token
$timestamp = time();
$expire_date = time() + 24*60*60;
$token_key = md5($timestamp.md5($email));
$statement = $conn->prepare("INSERT INTO `passwordrecovery` (userid, token, expire_date) VALUES (:userid, :token, :expire_date)");
$statement->bindParam(':userid', $userid);
$statement->bindParam(':token', $token_key);
$statement->bindParam(':expire_date', $expire_date);
$statement->execute();
//send email via amazon ses
include 'send-email-service.php';
$SendEmailService = new SendEmailService();
$reset_url = 'https://www.bjjtracker.com/reset-pw.php?token='.$token_key;
$subject = 'Reset your password.';
$body = 'Click here to reset your password: <a href="'.$reset_url.'">'. $reset_url .'</a>';
$altBody = 'Click here to reset your password: ' . $reset_url;
$this->status = $SendEmailService -> sendEmail($subject, $body, $altBody, $email);
}else{
$this->emailFound = 0;
}
}
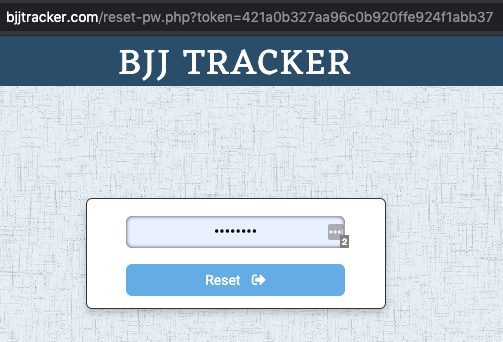
That link navigates to a page with a “reset password” form.
Upon submission the new password and embedded token are passed along to the server.
$(document).ready(function() {
$(".reset-button").click(function(){
var newPassword = $(".password-reset-input").val();
if(newPassword.length < 1){
var notifications = new UINotifications();
notifications.showStatusMessage("Please don't leave that blank :( ");
return;
}
var data = $(".resetpw-form").serialize();
$.ajax({
url: "/service-layer/user-service.php?method=resetPw&token=<?php echo $_GET['token']; ?>",
method: "POST",
data: data,
complete: function(response){
// console.log(response);
window.location = "/";
}
});
});
$("input").keypress(function(e) {
if(e.which == 13) {
e.preventDefault();
$(".reset-button").click();
}
});
});
The correct recovery record is selected by using the token value. That provides the user ID of the account that we want to update. The token should be deleted once the database is updated.
function resetPw(){
$conn = $this->connection;
$token = $_GET['token'];
$password = $_POST['password'];
$passwordHash = password_hash($password, PASSWORD_DEFAULT);
$statement = $conn->prepare("SELECT * FROM `passwordrecovery` where token = ?");
$statement->execute(array($token));
$row = $statement->fetch(PDO::FETCH_ASSOC);
$userid = $row['userid'];
$update_statement = $conn->prepare("UPDATE `users` SET password = ? where ID = ?");
$update_statement->execute(array($passwordHash, $userid));
$delete_statement = $conn->prepare("DELETE FROM `passwordrecovery` where token = ?");
$delete_statement->execute(array($token));
}
This is a secure and user-friendly workflow to allow users to reset their passwords.
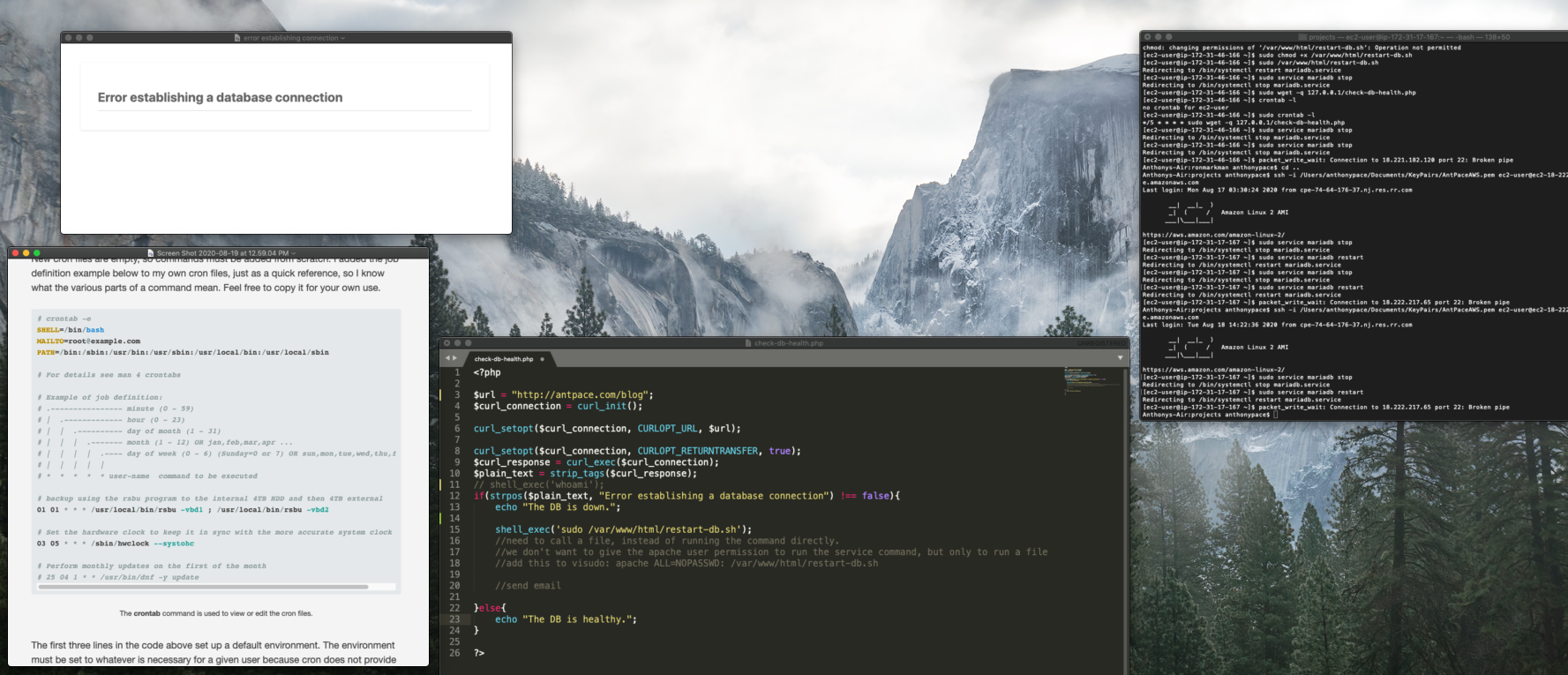
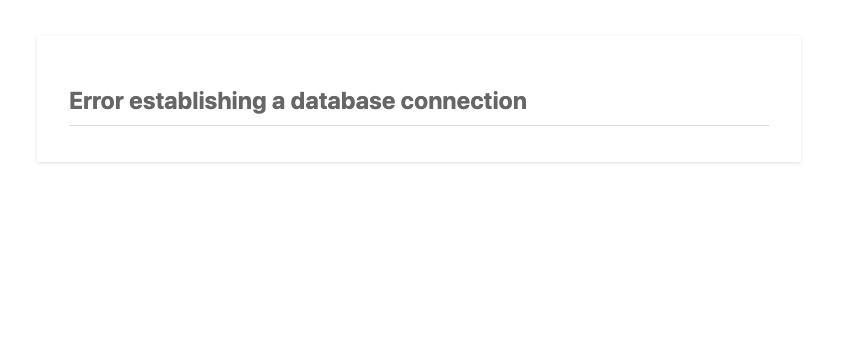
A crashed database is a problem I’ve encountered across multiple WordPress websites. When trying to load the site you’re faced with a dreaded “Error establishing a database connection” message. Restarting the DB service usually clears things up. But, sometimes it won’t restart at all – which is why I started automating nightly data dumps to an S3 bucket.
Recently, one particular site kept going down unusually often. I assumed it was happening due to low computing resources on the EC2 t3.micro instance. I decide to spin up a a new box with more RAM (t3.small) and migrate the entire WordPress setup.
Since I couldn’t be sure of what was causing the issue, I needed a way to monitor the health of my WordPress websites. I decided to write code that would periodically ping the site, and if it is down send an email alert and attempt to restart the database.
The first challenge was determining the status of the database. Even if it crashed, my site would still return a 200 OK response. I figured I could use cURL to get the homepage content, and then strip out any HTML tags to check the text output. If the text did match the error message, I could take further action.
Next, I needed to programmatically restart MySql. This is the command I run to do it manually: sudo service mariadb restart
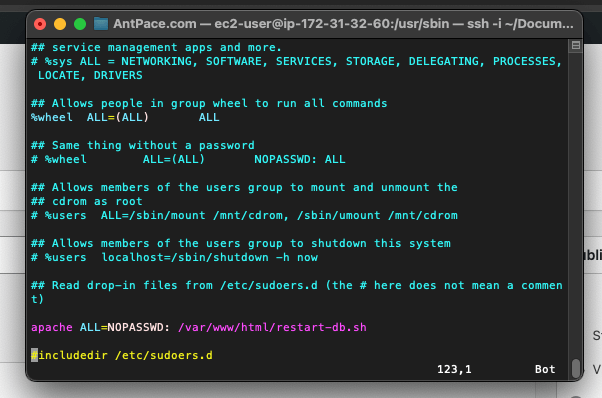
After doing some research, I found that I could use shell_exec() to run it from my PHP code. Unfortunately, Apache wouldn’t let the (non-password using) web server user execute that without special authorization. I moved that command to its own restart-db.sh file, and allowed my code to run it by adding this to the visudo file: apache ALL=NOPASSWD: /var/www/html/restart-db.sh
My visudo file was located at /usr/sbin/visudo. It is a tool found on most Linux systems to safely update the /etc/sudoers file, which is the configuration file for the sudo command. To edit this file, I don’t open it in vim like I would with other editable files. Instead, I run the file as its own command: sudo visudo. Once it is open, you can press the i key to enter “insert” mode. It is considered “safe” because it edits the sudoers file following a strict procedure.
I also needed to make the file executable by adjusting permissions: sudo chmod +x /var/www/html/restart-db.sh
Once those pieces were configured, my code would work:
<?php
$url = "https://www.antpace.com/blog/";
$curl_connection = curl_init();
curl_setopt($curl_connection, CURLOPT_URL, $url);
curl_setopt($curl_connection, CURLOPT_RETURNTRANSFER, true);
$curl_response = curl_exec($curl_connection);
$plain_text = strip_tags($curl_response);
if(strpos($plain_text, "Error establishing a database connection") !== false){
echo "The DB is down.";
//restart the database
shell_exec('sudo /var/www/html/restart-db.sh');
//send notification email
include 'send-email.php';
send_email();
}else{
echo "The DB is healthy.";
}
?>
A cron job is a scheduled task in Linux that runs at set times. For my PHP code to effectively monitor the health of the database, it needs to run often. I decided to execute it every five minutes. Below are three shell commands to create a cron job.
The first creates the cron file for the root user:
sudo touch /var/spool/cron/root
The next appends my cron command to that file:
echo "*/5 * * * * sudo wget -q https://www.antpace.com/check-db-health.php" | sudo tee -a /var/spool/cron/root
And, the last sets the cron software to listen for that file:
sudo crontab /var/spool/cron/root
Alternatively, you can create, edit, and set the cron file directly by running sudo crontab -e . The contents of the cron file can be confirmed by running sudo crontab -l .
Pro-tip: If your WordPress site does continually crash, you probably do need to upgrade to an instance with more RAM. Also, consider using RDS for the database.
Update
I previously used the localhost loop back address in my cron file: */5 * * * * sudo wget -q 127.0.0.1/check-db-health.php. After setting up 301 redirects to prevent traffic from hitting my public DNS, that stopped working. It is more reliable to use an explicit domain name URL: */5 * * * * sudo wget -q https://www.antpace.com/check-db-health.php
In a previous article I discussed launching a website on AWS. The project was framed as transferring a static site from another hosting provider. This post will extend that to migrating a dynamic WordPress site with existing content.
Install WordPress
After following the steps to launch your website to a new AWS EC2 instance, you’ll be able to connect via sFTP. I use FileZilla as my client. You’ll need the hostname (public DNS), username (ec2-user in this example), and key file for access. The latest version of WordPress can be downloaded from wordpress.org. Once connected to the server, I copy those files to the root web directory for my setup: /var/www/html
Make sure the wp-config.php file has the correct details (username, password) for your database. You should use the same database name from the previous hosting environment.
Data backup and import
It is crucial to be sure we don’t lose any data. I make a MySql dump of the current database and copy the entire wp-content folder to my local machine. I’m careful to not delete or cancel the old server until I am sure the new one is working identically.
Install phpMyAdmin
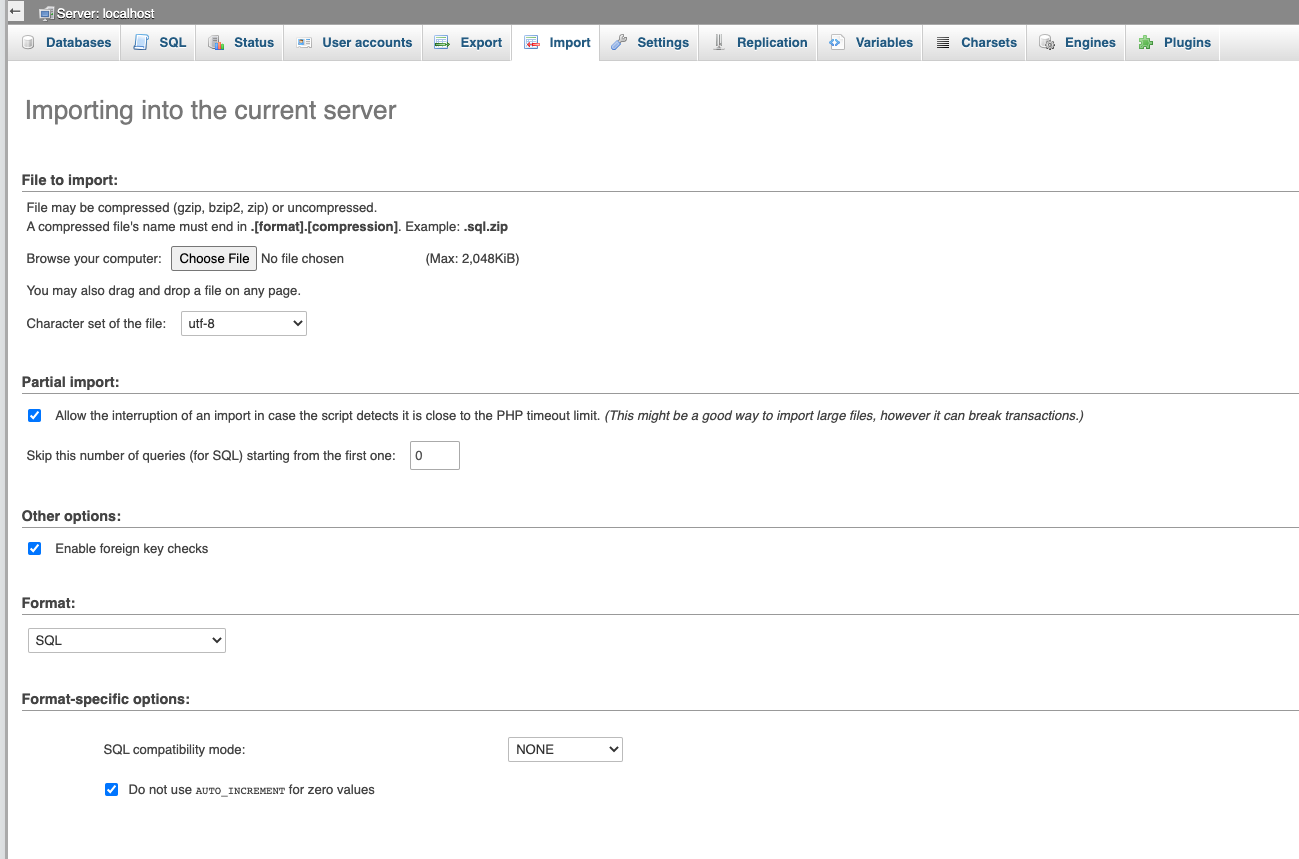
After configuring my EC2 instance, I install phpMyAdmin so that I can easily import the sql file.
The above Linux commands installs the database management software on the root directory of the new web server. It is accessible from a browser via yourdomainname.com/phpMyAdmin. This tool is used to upload the data to the new environment.
Create the database and make sure the name matches what’s in wp-config.php from the last step. Now you’ll be able to upload your .sql file.
Next, I take the wp-content folder that I stored on my computer, and copy it over to the new remote. At this point, the site homepage will load correctly. You might notice other pages won’t resolve, and will produce a 404 “not found” response. That error has to do with certain Apache settings, and can be fixed by tweaking some options.
Server settings
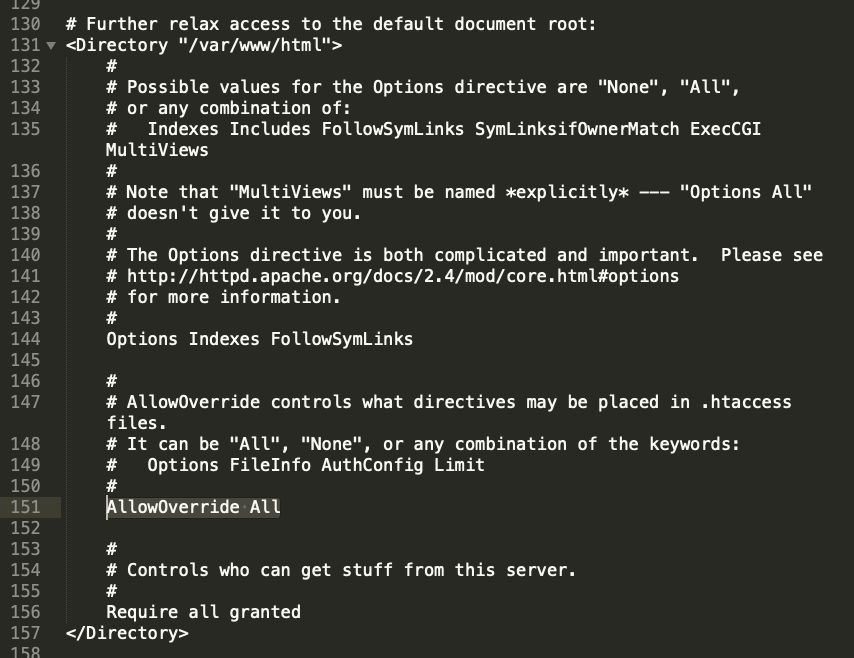
With my setup, I encountered the above issue with page permalinks . WordPress relies on the .htaccess file to route pages/posts with their correct URL slugs. By default, this Apache setup does not allow its settings to be overridden by .htaccess directives. To fix this issue, the httpd.conf file needs to be edited. Mine was located in this directory: /etc/httpd/conf
You’ll need to find (or create) a section that corresponds to the default document root: <Directory “/var/www/html”></Directory>. In that block, they’ll be a AllowOverride command that is set to “None”. That needs to be changed to “All” for our configuration file to work.
Final steps
After all the data and content has been transferred, do some smoke-testing. Try out as many pages and features as you can to make sure the new site is working as it should. Make sure you keep a back-up of everything some place secure (I use an S3 bucket). Once satisfied, you can switch your domain’s A records to point at the new box. Since the old and new servers will appear identical, I add a console.log(“new server”) to the header file. That allows me tell when the DNS update has finally resolved. Afterwards, I can safely cancel/decommission the old web hosting package.
In 2023, I used this blog post to stand-up a WordPress website. I was using a theme called Balasana. When I would try to set “Site Icon” (favicon) from the “customize” UI I would receive a message stating that “there has been an error cropping your image“. After a few Google searches, and also asking ChatGPT, the answer seemed to be that GD (a graphics library) was either not installed or not working properly. I played with that for almost an hour, but with no success. GD was installed, and so was ImageMagick (a back-up graphics library that WordPress falls back on).
The correct answer was that I needed to upgrade PHP. The AWS Linux 2 image comes with PHP 7.2. Upgrading to version 7.4 did the trick. I was able to make that happen, very painlessly, by following a blog post from Gregg Borodaty . The title of his post is “Amazon Linux 2: Upgrading from PHP 7.2 to PHP 7.4” (thanks Gregg).
I have had some lousy luck with databases. In 2018, I created a fitness app for martial artists, and quickly gained over a hundred users in the first week. Shortly after, the server stopped resolving and I didn’t know why. I tried restarting it, but that didn’t help. Then, I stopped the EC2 instance from my AWS console. Little did I know, that would wipe the all of the data from that box. Ouch.
Recently, a client let me know that their site wasn’t working. A dreaded “error connecting to the database” message was all that resolved. I’d seen this one before – no sweat. Restarting the database usually does the trick: “sudo service mariadb restart”. The command line barked back at me: “Job for mariadb.service failed because the control process exited with error code.”
Uh-oh.
The database was corrupted. It needed to be deleted and reinstalled. Fortunately, I just happen to have a SQL dump for this site saved on my desktop. This was no way to live – in fear of the whims of servers.
Part of the issue is that I’m running MySQL on the same EC2 instance as the web server. A more sophisticated architecture would move the database to RDS. This would provide automated backups, patches, and maintenance. It also costs more.
To keep cost low, I decided to automate MySQL dumps and upload to an S3 bucket. S3 storage is cheap ($0.20/GB), and data transfer from EC2 is free.
Deleting and Reinstalling the Database
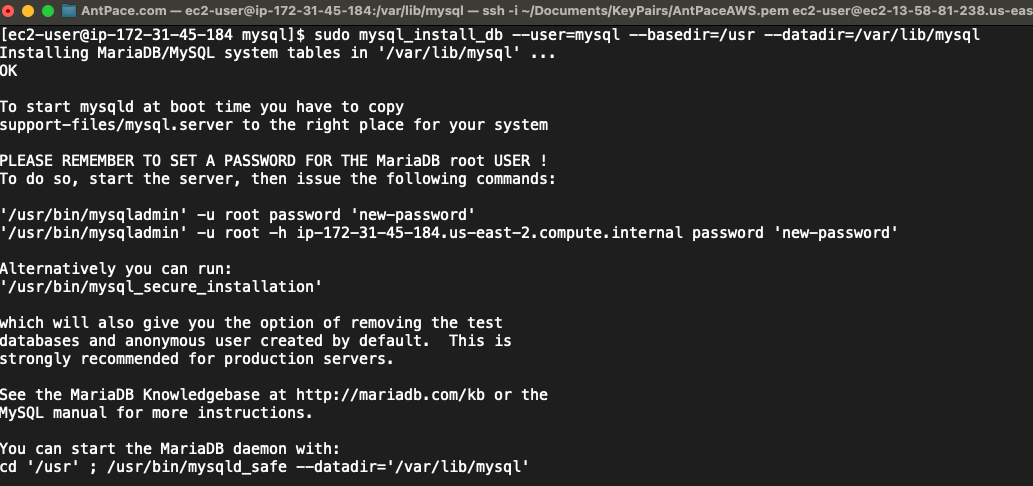
If your existing database did crash and become corrupt, you’ll need to delete and reinstall it. To reset the database, I SSH’d into my EC2 instance. I navigated to `/var/lib/mysql`
cd /var/lib/mysql
Next, I deleted everything in that folder:
sudo rm -r *
Finally, I ran a command to reinitialize the database directory
Afterwards, you’ll be prompted to reset the root password.
You’ll still need to import your sql dump backups. I used phpMyAdmin to do that.
Scheduled backups
AWS Setup
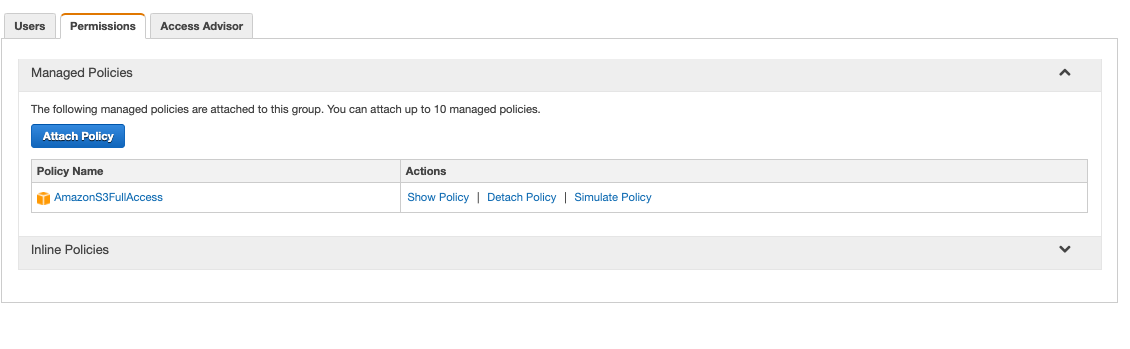
The first step was to get things configured in my Amazon Web Services (AWS) console. I created a new S3 bucket. I also created a new IAM user, and added it to a group that included the permission policy “AmazonS3FullAccess”.
This policy provides full access to all buckets.
I went to the security credentials for that user, and copied down the access key ID and secret. I would use that info to access my S3 bucket programatically. All of the remaining steps take place from the command line, via SSH, against my server. From a Mac terminal, you could use a command like this to connect to an EC2 instance:
Shell scripts are programs that can be run directly by Linux. They’re great for automating tasks. To create the file on my server I ran: “nano backup.sh”. This assumes you already have the nano text editor installed. If not: “sudo yum install nano” (or, “sudo apt install nano”, depending on your Linux flavor).
Below is the full code I used. I’ll explain what each part of it does.
The first line tells the system what interpreter to use: “#!/bin/bash”. Bash is a variation of the shell scripting language. The next eight lines are variables that contain details about my AWS S3 bucket, and the MySQL database connection.
After switching to a temporary directory, the filename is built. The name of the file is set to the database’s name plus the day of the week. If that file already exists (from the week previous), it’ll be overwritten. Next, the sql file is created using mysqldump and the database connection variables from above. Once that operation is complete, then we zip the file, upload it to S3, and delete the zip from our temp folder.
If the mysqldump operation fails, we spit out an error message and exit the program. (Exit code 1 is a general catchall for errors. Anything other than 0 is considered an error. Valid error codes range between 1 and 255.)
Before this shell script can be used, we need to change its file permissions so that it is executable: “chmod +x backup.sh”
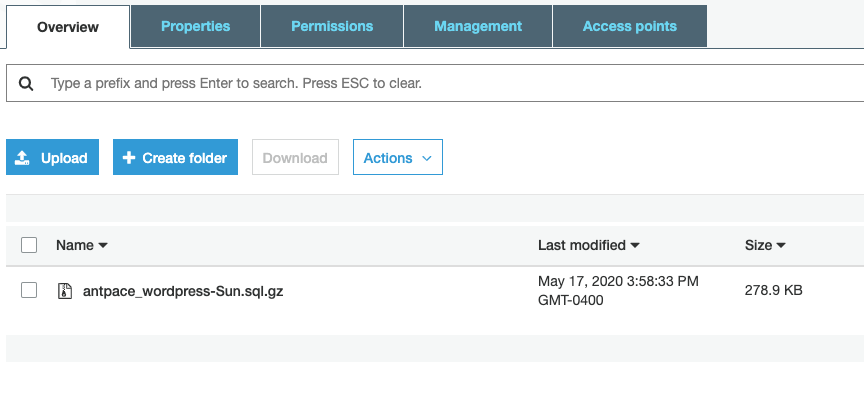
After all of this, I ran the file manually, and made sure it worked: “./backup.sh”
Sure enough, I received a success message. I also checked the S3 bucket and made sure the file was there.
Scheduled Cronjob
The last part is to schedule this script to run every night. To do this, we’ll edit the Linux crontab file: “sudo crontab -e”. This file controls cronjobs – which are scheduled tasks that the system will run at set times.
The file opened in my terminal window using the vim text editor – which is notoriously harder to use than the nano editor we used before.
I had to hit ‘i’ to enter insertion mode. Then I right clicked, and pasted in my cronjob code. Then I pressed the escape key to exit insertion mode. Finally, I typed “wq!” to save my changes and quit.
And that’s it. I made sure to check the next day to make sure my cronjob worked (it did). Hopefully now, I won’t lose production data ever again!
Updates
Request Time Too Skewed (update)
A while after setting this up, I randomly checked my S3 buckets to make sure everything was still working. Although it had been for most of my sites, one had not been backed up in almost 2 months! I shelled into that machine, and tried running the script manually. Sure enough, I received an error: “An error occurred (RequestTimeTooSkewed) when calling the PutObject operation: The difference between the request time and the current time is too large.“
I checked the operating system’s current date and time, and it was off by 5 days. I’m not sure how that happened. I fixed it by installing and running “Network Time Protocol”:
sudo yum install ntp sudo ntpdate ntp.ubuntu.com
After that, I was able to run my backup script successfully, without any S3 errors.
Nano text-editor tip I learned along the way:
You can delete chunks of text content using Nano. Use CTRL + Shift + 6 to enter selection mode, move the cursor to expand the block, and press CTRL + K to delete it.